



IBM has combined Data Lakehouse and Parallel File System capabilities to deliver a scalable, machine learning-based AI processing and analytics data storage platform using its watsonx.data and Storage Scale products.
This gives, IBM claimsextreme AI performance with GPU Direct Storage (GDS) and Nvidia to train generative AI models faster. There is multi-protocol support enabling simpler workflows, a unified data platform for analytics and AI, and the system supports recovery augmented generation (RAG) using a customer’s proprietary data.
Big Blue’s watsonx.data is a data lakehouse. It combines the features of a data lake – based on a scale-out architecture using standard servers and capable of storing and processing large volumes of structured and unstructured data – with the performance of a data warehouse. It supports the Apache Iceberg open table format allowing different processing engines to access the same data at the same time.
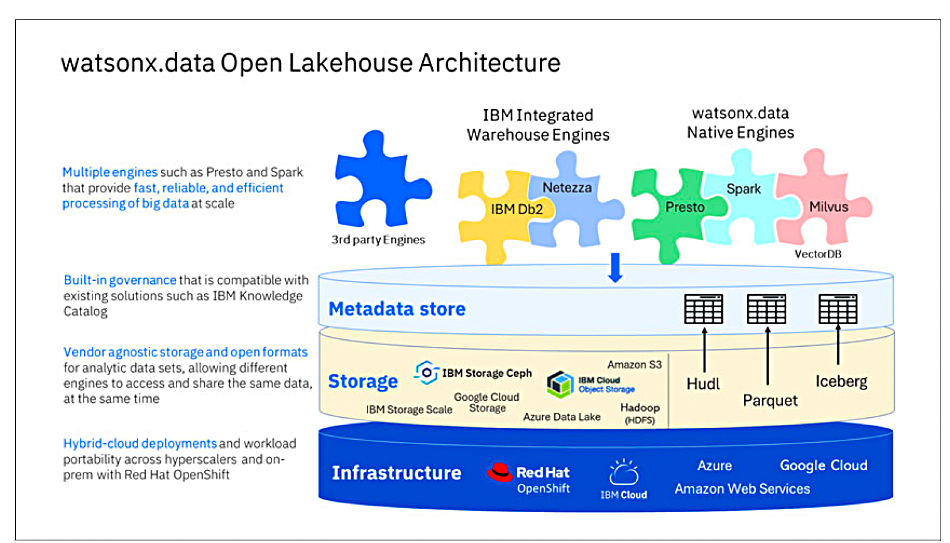
Storage Scale is a parallel and scalable file system originally called GPFS. It is used as a storage layer under watson.x.data, providing object storage capabilities under a file access overlay. V5.2.1 Storage Scale has a high-performance, non-containerized S3 protocol service that provides this.
How it fits together
An IBM diagram, with addition B&F yellow box elements, presents the software components:
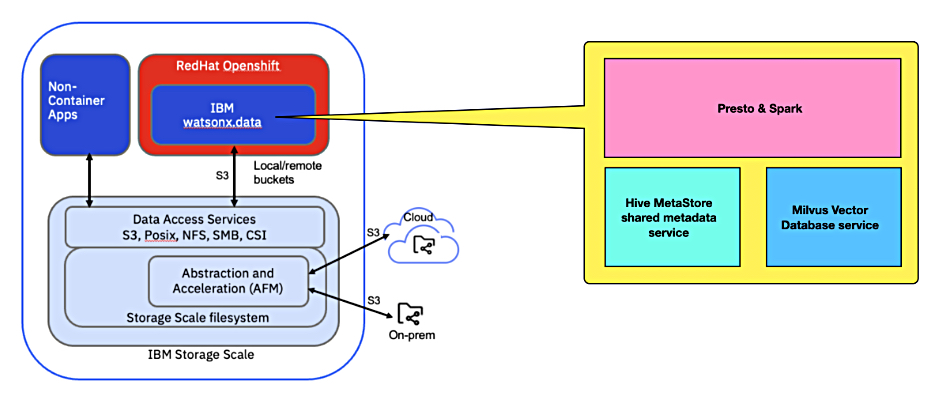
There are separate, disaggregated compute and storage layers. For compute, a Red Hat OpenShift container cluster foundation is used by watsonx.data applications, which include Presto and Spark. Presto provides data lake analytics using a distributed SQL query engine while Spark is an in-memory big data processing and analytics resource.
There is also a Hive Metastore providing a shared metadata service and a Milvus vector database service in this layer. Milvus is used to enable RAG by accessing a customer’s potentially large datasets residing on Storage Scale.
The separate storage infrastructure consists of three main elements: Storage Scale file system clusters that hold the data; Active File Management (AFM) for storage abstraction and acceleration; and the S3 Data Access Protocol service for high-performance object access.
The S3 service exposes object storage buckets to watsonx.data to attach to a query engine such as Presto or Spark. S3 objects are mapped to files and buckets are mapped to directories in Storage Scale and vice versa.
S3 buckets can be local to the storage layer or cached (and therefore accelerated) by Storage Scale from external object stores that can be globally dispersed across different clouds, data centers, and locations. In both cases, multiple Spark and Presto engine instances connect to the Storage Scale layer using the S3 protocol to access the buckets.
AFM features local caching and enables data sharing across clusters, by virtualizing remote S3 buckets at the fileset level. It implements a global namespace across Storage Scale clusters and can include NFS Data Sources in this namespace as well. Remote S3 buckets appear as local buckets under the Storage Scale file system, under a common storage namespace. This eliminates the need for data copies.
Remote S3 bucket virtualization is powered by Storage Scale High Performance S3, which is based on the open source software NooBaa. It is an object storage software that uses X86 servers and storage, packaged as an S3-like cloud service. Noobaa was acquired by Red Hat in 2018 and abstracts storage infrastructure in hybrid multicloud environments. It also provides data storage service management. Red Hat has integrated it into its OpenShift Data Foundation (ODF) product set. IBM acquired Red Hat in 2019 and ODF added to its then Spectrum Fusion offering – now Storage Fusion – as well as the existing containerized version of Spectrum Scale and Spectrum Protect data protection.
NOW NooBaa is a customizable and dynamic data gateway for objects, providing data services such as caching, tiering, mirroring, deduplication, encryption, and compression, on any storage resource, including S3, GCS, Azure Blob, file systems, and more.
Storage Scale’s high-performance Object S3 service is optimized for multiprotocol data access. It replaces the Swift-based Object S3 and Containerized S3 service implementations in Storage Scale. A Cluster Export Services (CES) feature within Storage Scale manages high availability through CES nodes.
Multiple levels
IBM says there can be multiple performance tiers for Storage Scale storage, to optimize cost and performance. There can be a high-performance tier for hot data, as well as a cost-effective tier or even tape for long-term storage and archiving, as well as automated policy-based placement across multiple tiers, making tiering seamless and transparent to applications.
This combined watsonx.data and Storage Scale system provides a unified but disaggregated compute and storage platform on which to run AI applications for training and inference. Customers may appreciate this because IBM acts as a single source for the required software. We have covered other AI data platform approaches from Dell, HPE, Lenovo, NetApp, MinIO And Purewith VAST Data preparing its own Data Engine offer.
The watsonx.data and Storage Scale AI bundle is described in a IBM Red Book which “shows how IBM watsonx.data applications can benefit from the enterprise storage features and capabilities offered by IBM Storage Scale.”
You can read more about the latest watsonx.data v2.0.2 release in the release notes here.