


Organizations can use retrieval-augmented generation with large language models to democratize data analysis, reducing the technical skills barrier employees need to use data in everyday tasks.
LLMs provide advanced capabilities to translate data queries into responses that any user can understand. CLOTH guarantees the most accurate results possible.
The growing popularity of LLMs is due to their sophisticated ability to analyze, categorize, and process complex user queries in ways that mimic human interaction. LLMs can provide answers to questions, condense articles, and create descriptive captions.
Despite their remarkable capabilities, LLMs have their limitations. They sometimes produce answers that may be inaccurate, outdated, or off-topic. Inaccuracies occur primarily because of their reliance on pre-existing datasets that may not include the most recent or detailed information users are looking for.
The RAG can help mitigate these challenges in the responses generated by the LLM.
How LLMs work
LLMs are sophisticated algorithms created by processing vast amounts of textual data from a variety of sources, including books, websites, and articles. They use advanced machine learning techniques to codify the complexities, subtleties, and patterns of human language. These capabilities help LLMs discern and reproduce relationships between concepts within data sets. in-depth trainingLLMs can generate human-like responses in terms of style and content.
When a user enters a prompt in an LLM, the model uses its training to generate relevant and contextually nuanced text. The process involves analyzing the prompt, determining the most appropriate response based on the learned patterns, and constructing a coherent and contextually appropriate response.
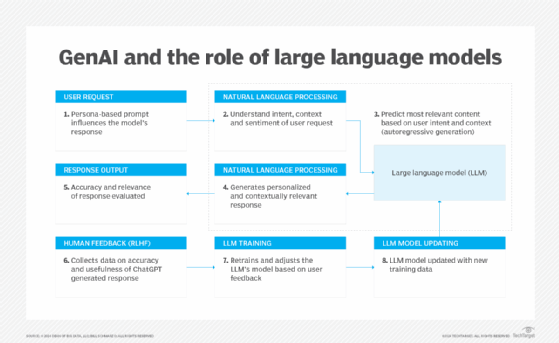
LLMs can improve user engagement with digital information. They play a critical role in democratizing access to data and dismantling traditional barriers to knowledge and expertise. LLMs can open new avenues of understanding and learning for individuals by distilling complex data into accessible language.
How RAG Improves LLM Performance
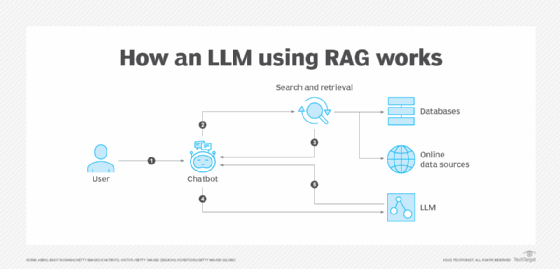
RAG intercepts a query before it reaches a public LLM and augments the user’s query with proprietary organizational data. It passes the modified prompt to the LLM to obtain a more precise and relevant response.
RAG is a cost-effective and scalable way to improve the quality and usefulness of LLMs without having to retrain models on new data. RAG works for any domain or task that requires external knowledge, such as medical diagnosis, legal advice, or product evaluations. Users can customize RAG to use different knowledge sources, such as data or proprietary information, based on their specific needs and preferences.
For example, let’s say you ask an LLM to write a summary of the latest news about COVID-19. The LLM may not have the most recent or reliable data on the pandemic and may generate an outdated or inaccurate summary. But RAG, with a knowledge source containing the latest news articles and statistics about COVID-19, can extract the most relevant information from the knowledge source and supplement your request with that information. The LLM can then generate a summary based on the augmented request, reflecting the current situation and facts about COVID-19.
The RAG Rapid Intercept process streamlines obtaining highly relevant responses through a simple four-step methodology:
- The user submits a request. The user asks a question or searches for specific information. This first step allows you to lay the foundations of the query and define the user’s intentions.
- Request intercepted and augmented. The RAG intercepts and completes the initial request. The enhancement refines the request, ensuring that it is prepared to elicit the most relevant and complete response possible from the LLM.
- Augmented request submitted to LLM. The RAG forwards the request to the LLM with additional details. Providing context ensures that the LLM’s response is accurate and meticulously tailored to address the nuances and specificities of the request.
- Personalized response returned. The answer, enriched by the previous steps, is a more precise and relevant response that matches the initial query. This personalized approach ensures an accurate response and uniquely adapts to each individual’s needs.
The future of LLM and RAG
The combination of LLMs and RAGs to perform tasks that traditionally require human intelligence is used in many industries, including education, customer service, and creative fields. Using RAGs with LLMs to democratize data Analytics and access can drive more informed decision-making, improve creativity and efficiency in problem-solving across a variety of domains. As technology evolves, the RAG-LLM combination can help make data more accessible, personal, relevant and actionable in several ways:
- Improved personalization and relevance. Future RAG systems may become better able to tailor responses to individuals using historical data, personal preferences, and context.
- Mixing knowledge between fields. RAG technology has applications in many industries, including healthcare, education, finance, and customer service. Integrating proprietary organizational data with LLMs’ vast knowledge base can provide deeper and more varied insights and answers. For example, RAG technology could enable more personalized patient care by combining medical literature with individual patient medical records.
- Real-time information update. As organizations continually update their databases, RAG systems can quickly integrate the most recent information.
- Bridging the knowledge gap. RAG has the potential to democratize knowledge by making specialized and hard-to-access information easily accessible to non-experts. This could level the playing field and allow small entities to access the same information as large organizations, thereby fostering innovation and competitive differentiation.
- Ethical and responsible use. The RAG is responsible for ensuring ethical and responsible use, including data privacy and security. Future developments should improve transparency, user consent protocols, and the ability to audit and explain data use and response generation.
- Combating prejudice and misinformation. Addressing the challenges posed by bias and misinformation in LLM harvested data and training data is essential. Future RAG systems must incorporate more sophisticated mechanisms to identify, mitigate, and correct bias.
- Human-AI collaborative interaction. The future of RAG involves closer collaboration between humans and AI. RAG systems have the potential not only to provide insights, but also to function as a partner in creative problem-solving, research, and innovation. This could lead to new forms of collaborative intelligence, where AI’s data processing and pattern recognition capabilities amplify human creativity and intuition.
Bill Schmarzo is the former CIO of Hitachi Vantara, where he was recognized for his groundbreaking work in data science and automated machine learning. He also worked at Dell EMC as CTO and as VP of Analytics at Yahoo. He has also written several books on big data.