

Originally published in ForbesAugust 27, 2024
This is the second in a series of three articles covering the business value of predictive AI, using misinformation detection as an example: item 1article 2, article 3.
Man, I wish I had a magic crystal ball. That would be practical.
Fortunately, we have the next best solution: probability, assigning a number between 0 and 100 to the chances of something happening. The way to calculate probabilities from historical data is machine learning. And enterprise deployment of ML to improve operations with these probabilities is called Predictive AI.
In my previous articleI covered one such use case: misinformation detection. I showed how, by predictively deciding which social media posts are worth an investment of human effort to audit, a social media company with a high-risk channel (one-third misinformation) can determine how much money she could save. The savings curve looked like this (explained in detail in this previous article):
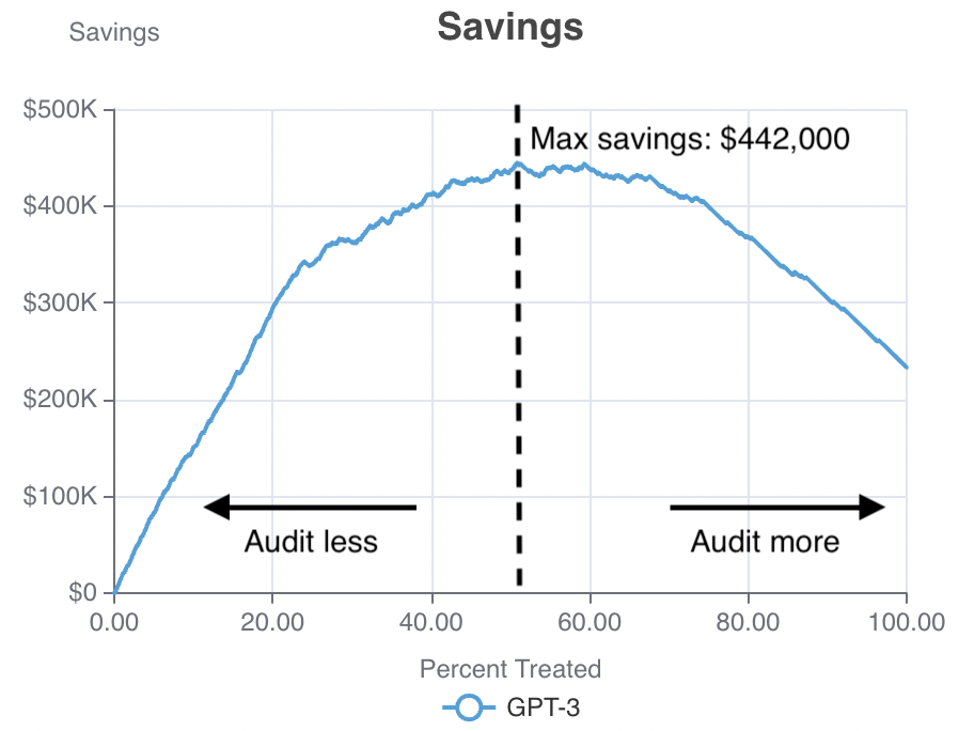
A savings curve for misinformation detection. The horizontal axis represents the share of positions audited manually and the vertical axis represents savings. – ERIC SIEGEL
There’s a reason we need to look at a curve like this rather than just a number. You might be tempted to view the maximum savings of $442,000 as the only thing you need. And this is indeed an option: if you define the decision threshold at 51% – as shown by the dotted line – then the model is estimated to save the company that much. With this setting, the riskiest 51% of posts, those to the left of the dotted line, will be audited.
Finding a balance between competing factors
But there are other factors to consider. Take a look at the shape of the curve. If you moved the decision threshold slightly to the right, say to 60%, you would get a good compromise: you would block more misinformation with only a very slight decrease in savings.
Another factor to consider could be the absolute number of erroneous indicators, i.e. false positives. Any time a truthful message is flagged as potentially erroneous, there is a potential downside, beyond the cost of unnecessary human auditing. Suppose the system works as follows: when a message is flagged, it is suppressed at least temporarily until a human listener verifies it. This means that the social media user has to face an unusual delay in publishing their post, as well as the feeling of distrust. The further we move the dashed decision threshold to the right in the graph above, the more misinformation captured, but the more false positives.
Another consideration could also be the total cost of the auditors. If the organization imposes a budget on the audit team, this means that a limited number of positions can be audited each week, so there will be very few left to set the decision threshold . For example, you may only be able to afford to audit the riskiest 20% of posts, in which case the 20% mark will be the furthest to the right you can achieve.
Finally, the steepness of the curve makes a difference. If the powers that be impose this maximum of 20%, you could point out to them that the curve continues its strong upward trajectory up to the 23% mark. This means you could continue to get relatively high bang for your buck a little beyond the 20% mark, blocking misinformation and increasing your savings at the same high rate. This might convince your decision-makers that it would be worth increasing the budget a little more.
The whole curve counts. Only by observing its deviations and turns throughout can you consider all available options and compromises. Rather than looking at a single number in isolation to evaluate a model and determine if and how to deploy it, your team should work with visuals like a savings or profit curve that present the full range of model deployment options.
In a follow-up article, I’ll continue with this example to show how business factors might be changed or reconsidered, such as the value your company places on preventing misinformation or preventing any problems the project seeks to avoid, affect deployment decisions. . As you will see, changing the settings for these factors changes the shape of the curve and therefore changes your deployment options.
About the author
Eric Siegel is a leading consultant and former professor at Columbia University who helps companies deploy machine learning. He is the founder of the long-running group Machine Learning Week lecture series, the instructor of the famous online course “Machine Learning Leadership and Practice – End-to-End Mastery», editor-in-chief of Time for machine learning and a frequent keynote speaker. He wrote the best-seller Predictive Analytics: The power to predict who will click, buy, lie or diewhich has been used in courses at hundreds of universities, as well as The AI Handbook: Mastering the Rare Art of Deploying Machine Learning. Eric’s interdisciplinary work bridges the stubborn gap between technology and business. At Columbia, he won the Distinguished Faculty Award for teaching senior computer science courses in ML and AI. He later served as a business school professor at UVA Darden. Eric also publishes opinion pieces on analysis and social justice. You can follow it LinkedIn.