


An AI system can malfunction if an adversary finds a way to disrupt its decision-making. In this example, erroneous road markings mislead a driverless car, potentially causing it to veer into oncoming traffic. This “evasion” attack is one of several adversarial tactics outlined in a new NIST publication intended to help define the types of attacks we can expect as well as approaches to mitigate them.
Credit: N. Hanacek/NIST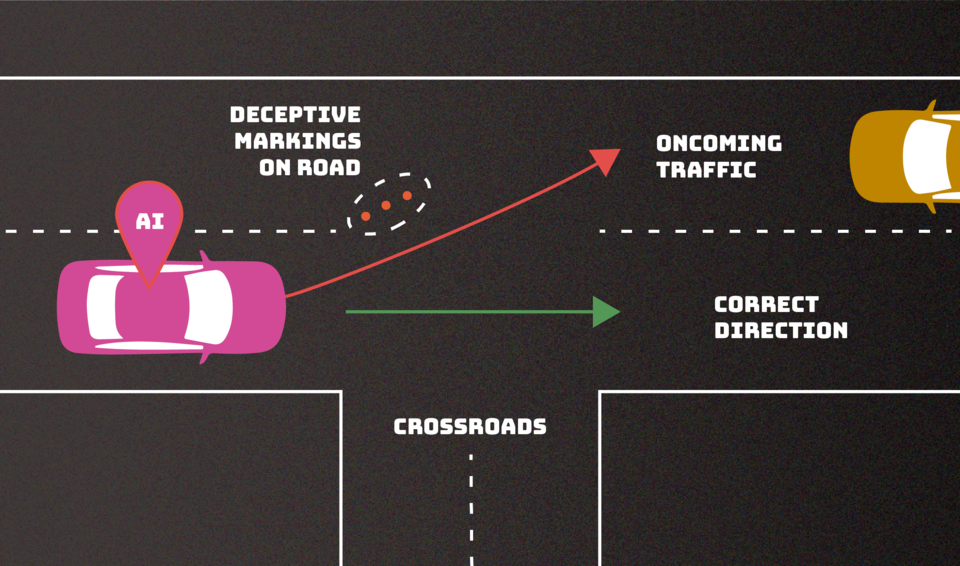
Adversaries can deliberately confuse or even “poison” artificial intelligence (AI) systems to make them malfunction – and there is no foolproof defense for their developers. Computer scientists at the National Institute of Standards and Technology (NIST) and their collaborators identify these and other AI and machine learning (ML) vulnerabilities in a new publication.
Their work, entitled Adversarial Machine Learning: A Taxonomy and Terminology of Attacks and Mitigation (NIST.AI.100-2)is part of NIST’s broader effort to support the development of Trustworthy AI, and it can help put NIST’s AI risk management framework into practice. The publication, a collaboration between government, academia and industry, aims to help AI developers and users understand the types of attacks they can expect as well as approaches to mitigate, it being understood that there is no miracle solution.
“We provide an overview of attack techniques and methodologies that take into account all types of AI systems,” said NIST computer scientist Apostol Vassilev, one of the publication’s authors. “We also describe current mitigation strategies reported in the literature, but these available defenses currently lack strong assurances that they fully mitigate risks. We encourage the community to come up with better defenses.
AI systems have permeated modern society, working in areas ranging from driving vehicles to helping doctors diagnose illnesses to interacting with customers as online chatbots. To learn how to perform these tasks, they are trained on large amounts of data: for example, an autonomous vehicle can see images of highways and streets with traffic signs, while a chatbot based on a large model of language (LLM) can be exposed to images of highways and streets with traffic signs, for example. recordings of online conversations. This data helps AI predict how to react in a given situation.
A major problem is that the data itself may be unreliable. Its sources can be websites and interactions with the public. There are many opportunities for malicious actors to corrupt this data, both during the training period of an AI system and afterward, as the AI continues to refine its behaviors by interacting with the physical world. This may cause the AI to operate undesirably. Chatbots, for example, can learn to respond with abusive or racist language when their guardrails are circumvented by carefully crafted malicious prompts.
“For the most part, software developers need more people to use their product so that it can improve with exposure,” Vassilev said. “But there is no guarantee that the exposure will be good. A chatbot can spread misinformation or toxic information when prompted in carefully crafted language.
Partly because the datasets used to train AI are far too large for people to successfully monitor and filter, there is not yet a foolproof way to protect AI from misdirection . To help the developer community, the new report provides insight into the types of attacks its AI products could experience and corresponding approaches to reduce the damage.
The report examines the four main types of attacks: evasion, poisoning, privacy, and abuse attacks. It also ranks them according to several criteria such as the attacker’s goals and objectives, his abilities and his knowledge.
Escape attacks, which occur after an AI system is deployed, attempt to modify an input to change how the system responds to it. Examples could include adding markings to stop signs so that an autonomous vehicle misinterprets them as speed limit signs or creating confusing lane markings to cause the vehicle to swerve of the road.
Poisoning attacks occur in the training phase by introducing corrupted data. An example would be slipping many instances of inappropriate language into conversation recordings, so that a chatbot interprets these instances as common enough language to use in its own interactions with customers.
Confidentiality attacks, which occur during deployment, are attempts to obtain sensitive information about the AI or the data it was trained on in order to misuse it. An adversary can ask a chatbot many legitimate questions, then use the answers to reverse engineer the model to find its weak points – or guess its sources. Adding unwanted examples to these online sources could cause the AI to behave inappropriately, and getting the AI to unlearn these specific unwanted examples after the fact can be difficult.
Abuse attacks involve inserting incorrect information into a source, such as a web page or online document, which an AI then absorbs. Unlike the aforementioned poisoning attacks, abusive attacks attempt to feed the AI with incorrect information from a legitimate but compromised source in order to repurpose the intended use of the AI system.
“Most of these attacks are fairly easy to mount and require minimal knowledge of the AI system and limited adversarial capabilities,” said co-author Alina Oprea, a professor at Northeastern University. “Poisoning attacks, for example, can be staged by monitoring a few dozen training samples, which would be a very small percentage of the entire training set.”
The authors – which also included Robust Intelligence Inc. researchers Alie Fordyce and Hyrum Anderson – break down each of these classes of attacks into subcategories and add approaches to mitigate them, although the publication acknowledges that the defenses that experts in AI have been designed so far for adversarial attacks. are incomplete at best. Awareness of these limitations is important for developers and organizations looking to deploy and use AI technology, Vassilev said.
“Despite the significant advances made by AI and machine learning, these technologies are vulnerable to attacks that can cause spectacular outages with disastrous consequences,” he said. “There are theoretical problems related to securing AI algorithms that simply have not yet been resolved. If anyone says otherwise, they are selling snake oil.