


Over the last decade, data-driven method using deep neural networks has enabled artificial intelligence to succeed in various challenging applications in different domains. These advances address multiple problems. However, existing methodologies face this challenge in data science applications, especially in domains such as biology, healthcare, and business, due to the need for deep expertise and advanced coding skills. Moreover, a significant obstacle in this field is the lack of communication between domain experts and advanced artificial intelligence models.
In recent years, rapid advances in large language models (LLMs) have opened up many possibilities in artificial intelligence. Some of the most popular LLMs include GPT-3, GPT-4, PaLM, LLaMA, and Qwen. These models have great potential to understand, generate, and apply natural language. These advances have created a medium for LLM-based agents that are currently being developed to solve problems in search engines, software engineering, games, recommendation systems, and scientific experiments. These agents are often guided by a chain of thought (CoT) such as ReAct and can use tools such as APIs, code interpreters, and fetchers. The methods discussed in this paper include (a) enhancing LLMs with function calling and (b) feeding LLMs to a code interpreter.
A team of researchers from The Hong Kong Polytechnic University has presented LAMBDA, a novel open-source, no-code multi-agent data analysis system developed to overcome the lack of effective communication between domain experts and advanced AI models. LAMBDA provides a critical medium that enables seamless interaction between domain knowledge and AI capabilities in data science. This method solves many problems such as removing coding barriers, integrating human intelligence with AI, and reshaping data science education, promising reliability and portability. Reliability means that LAMBDA can handle data analysis tasks stably and correctly. Portability means that it is compatible with various LLMs, allowing it to be enhanced by the latest state-of-the-art models.
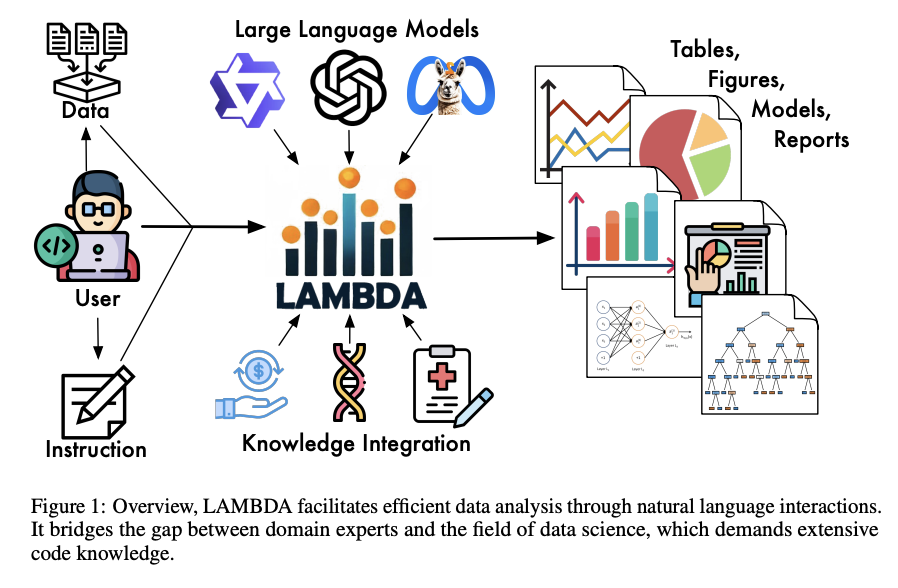
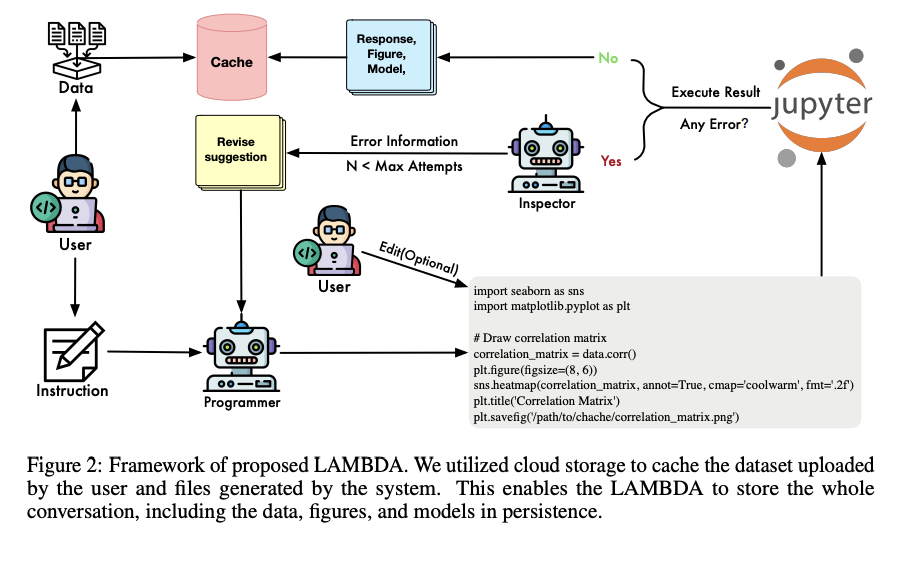
The proposed method, LAMBDA, a multi-agent data analysis system, contains two agents that work together to solve data analysis tasks using natural language. The process starts with writing code based on user instructions and then executing that code. The two main roles of LAMBDA are the “programmer” and the “inspector”. The programmer writes code according to the user’s instructions and data set. This code is then executed on the host system. If the code encounters errors during execution, the inspector plays the role of suggesting improvements. The programmer uses these suggestions to correct the code and submit it for re-evaluation.
The experimental results show that LAMBDA performs well in machine learning tasks. It achieved the highest accuracy rates of 89.67%, 100%, 98.07%, and 98.89% for AIDS, NHANES, Breast Cancer, and Wine datasets, respectively for classification tasks. For regression tasks, it achieved the lowest mean square error (MSE) of 0.2749, 0.0315, 0.4542, and 0.2528, respectively. These results highlight its effectiveness in handling various data science application models. Moreover, LAMBDA successfully overcame the coding barrier without any human intervention in the whole process of these experiments, and connected data science with human experts who lack coding skills,
In this paper, a team of researchers from the Hong Kong Polytechnic University proposed a novel open-source, no-code multi-agent data analysis system called LAMBDA, which combines human intelligence and AI. Experimental results show that it performs well in data analysis tasks. In the future, it can be improved with planning and reasoning techniques. It has bridged the gap between data science and humans without coding skills, successfully connecting them without human intervention. By bridging the gap between human expertise and AI capabilities, LAMBDA aims to make data science and analysis more accessible, thereby encouraging more innovation and discovery in the future.
Check Paper, ProjectAnd GitHub. All the credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel And LinkedIn Groops. If you like our work, you’ll love our bulletin..
Don’t forget to join us Over 47,000 ML subreddits
Find coming soon AI Webinars Here

Sajjad Ansari is a final year undergraduate student at IIT Kharagpur. Passionate about technology, he focuses on practical applications of AI with a focus on understanding the impact of AI technologies and their implications in the real world. He aims to articulate complex concepts of AI in a clear and accessible manner.