



To start up DataPelago has unveiled its Universal Data Processing Engine (UDPE), software that accelerates computation for data analysis and GenAI models.
DataPelago – a portmanteau of “data” and “archipelago” – claims to create a new data processing standard for the accelerated computing era to overcome the performance, cost and scalability limitations of software architectures and x86 processors. UDPE uses open source Gluten, Velox and Substrait to power Spark and Trino, providing customers with “game-changing price/performance benefits”. It integrates with existing data stores and Lakehouse platforms, SQL, Python, Airflow workflow automation, Tableau, Power BI, and more, without requiring data migration or lock-in.
DataPelago was founded in 2021 by CEO Rajan Goyal and Chief Product Officer Anand Iyer. Goyal was CTO at DPU to start up Fungibleacquired by Microsoft for approximately $190 million in 2022. Its history includes hardware/software co-design at Cavium. Think of the UDPE as a quasi-software DPU.

DataPelago has raised over $75 million in venture funding through an $8 million seed round in 2021, a $20 million A round in 2022, and a $47 million venture capital round. dollars this month. The latest round involved Eclipse, Taiwania Capital, Qualcomm Ventures, Alter Venture Partners, Nautilus Venture Partners and Silicon Valley Bank, a division of First Citizens Bank.
Goyal said: “Today, organizations face an insurmountable obstacle to unlocking breakthrough intelligence and innovation: processing an infinite sea of data… By applying non-linear thinking to overcome current limitations in data processing, we We built an engine capable of processing exponentially increasing volumes. complex data in various formats.
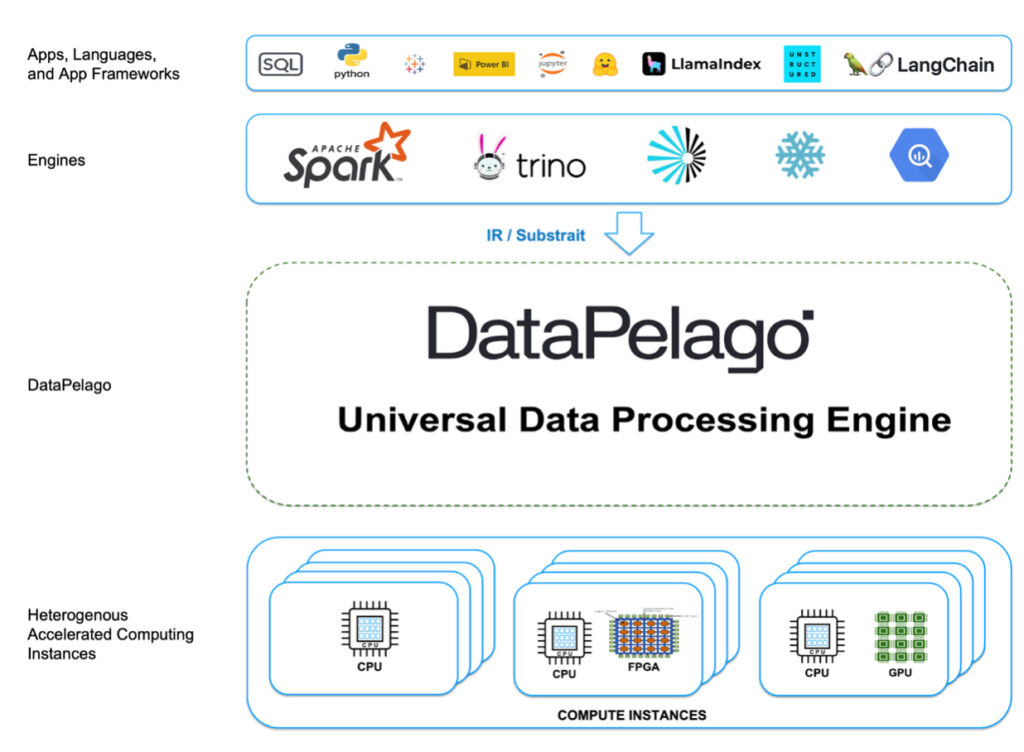
He told an investor that it would proceed by “first building a software-based query plan that leverages the inherent knowledge of the data to calculate adjacency and storage to calculate proximity.” In addition to this, he described his vision for creating networked query engines that could be used to achieve massively parallel query execution. These engines would support CPUs, GPUs, FPGAs and other acceleration hardware.
UDPE refactors data processing to exploit accelerated computing, leveraging higher degrees of parallelism and a tightly coupled memory model to deliver orders of magnitude better performance.
It has three layers of components:
- DataVM – a virtual machine with a domain-specific instruction set architecture (ISA) for data operators providing a common abstraction for execution on CPU, GPU, FPGA, and custom silicon.
- DataOS – The operating system layer maps data operations onto heterogeneous accelerated computing elements and manages them dynamically to optimize performance at scale.
- Data Application – a pluggable layer that allows integration with platforms such as Spark and Trino to provide acceleration capabilities to these engines.

The company says its UDPE is suitable for resource-intensive use cases, such as analyzing billions of transactions while ensuring data freshness and supporting AI-based models to detect threats to wireline speeds across millions of consumer and data center endpoints, and providing a scalable platform to facilitate the rapid deployment of RAG training, fine-tuning and inference pipelines.
UDPE is not a storage engine. A spokesperson said B&F: “A storage engine (like Speedb) is used to write and read data from storage disks and is written in low-level code. A storage engine cares about the placement of data on storage rather than the semantics of queries or data processing requests. DataPelago is a data processing engine for GenAI and analytics workloads. DataPelago sits higher in the technology stack. It focuses on processing queries/data processing requests and leaves the actual data placement to the underlying storage layer, which would include technologies such as the Speedb engine.
It “introduces enhancements that automatically map operations to the most appropriate computing hardware – whether a CPU, GPU, FPGA or other – and dynamically reconfigure these elements to maximize performance target hardware… (It) does not require any custom hardware and works outside the standard. Accelerated compute instances available in the cloud from hyperscalers like AWS, Azure, and GCP as well as new GPU cloud providers like CoreWeave, Crusoe, Lambda, etc. All this happens transparently to users, requiring no changes to queries, code. , applications, workflows, tools or processes.
Goyal writes about his experience founding DataPelago here.