


In 1950, weather forecasting began its digital revolution when researchers used the first general-purpose programmable computer. ENIAC solve mathematical equations describing the evolution of time. In the more than 70 years since, continued advances in computing power and improvements in model formulations have led to steady gains in weather forecasting skills: a 7-day forecast today Today is about as accurate as a 5-day forecast in 2000 and a 3-day forecast. one-day forecast in 1980. Although improving forecast accuracy at the rate of about one day per decade may not seem like a big deal, each day of improvement is important in large-scale use cases , such as logistics planning, disaster management, agriculture and energy. production. This “quiet” revolution has been extremely valuable to society, saving lives and providing economic value across many sectors.
Today we are witnessing the start of a new revolution in weather forecasting, this time fueled by advances in machine learning (ML). Rather than hard-coding approximations of physical equations, the idea is to allow algorithms to learn how the weather is changing by examining large volumes of past weather data. The first attempts in this direction date back to 2018 but the pace has accelerated significantly over the past two years, when several large ML models demonstrated weather forecasting skills comparable to those of the best physics-based models. Google MetNet (1, 2), for example, demonstrated cutting-edge capabilities to forecast regional weather a day in advance. For global prediction, Google DeepMind created GraphCasta graphical neural network for making 10-day predictions at 25 km horizontal resolution, competitive with the best physics-based models in many skill settings.
Besides potentially providing more accurate forecasts, one of the main advantages of these ML methods is that, once trained, they can create forecasts in minutes on inexpensive hardware. In contrast, traditional weather forecasting requires large supercomputers that run for hours each day. Clearly, ML represents a tremendous opportunity for the weather forecasting community. This has also been recognized by major weather forecasting centers, such as the European Center for Medium-Range Weather Forecasts (ECPMMT) machine learning roadmap or the National Oceanic and Atmospheric Administration (NOAA) artificial intelligence strategy.
To ensure that ML models are reliable and optimized to achieve the right goal, forecast evaluation is crucial. However, evaluating weather forecasts is not simple because weather is a multifaceted problem. Different end users are interested in different properties of forecasts: for example, renewable energy producers care about wind speed and solar radiation, while crisis response teams worry about the trajectory of a potential cyclone or an imminent heat wave. In other words, there is no single metric for determining what a “good” weather forecast is, and the assessment must reflect the multidimensional nature of weather and its downstream applications. Additionally, differences in the exact evaluation setup (e.g., resolution and ground truth data used) can make model comparison difficult. Having a way to compare new and established methods in a fair and reproducible manner is crucial to measuring progress in the field.
To this end, we announce WeatherBench 2 (WB2), a benchmark for the next generation of data-driven global weather models. WB2 is an update of original reference published in 2020, based on initial low-resolution ML models. The goal of WB2 is to accelerate the advancement of data-driven weather models by providing a reliable and repeatable framework for evaluating and comparing different methodologies. THE official website contains scores of several state-of-the-art models (at the time of writing these are Keisler (2022)one of the first graphical neural networks, that of Google DeepMind GraphCast and that of Huawei Pangu-Weathera transformer-based ML model). Additionally, forecasts from ECMWF’s high-resolution and ensemble forecast systems are included, which represent some of the best traditional weather forecasting models.
 |
Make assessment easier
The key element of WB2 is a open source evaluation framework which allows users to evaluate their forecasts in the same way as other benchmarks. High-resolution weather forecast data can be quite large, making even evaluating them a computational challenge. For this reason, we built our evaluation code on Apache beamwhich allows users to break calculations into smaller chunks and evaluate them in a distributed manner, e.g. using Data flow on Google Cloud. The code comes with a quick start guide to help people get up to speed.
Furthermore, we provide Most reference and ground truth data on Google Cloud Storage in a cloud-optimized format Zar format at different resolutions, for example, a complete copy of the ERA5 dataset used to train most ML models. This is part of a larger effort by Google to provide Analysis-ready, cloud-optimized weather and climate datasets to the research community and beyond. Since downloading this data from the respective archives and converting it can be time consuming and computationally intensive, we hope that this should significantly lower the entry barrier for the community.
Assessing Forecasting Skills
With our collaborators from ECMWFWe defined a set of master scores that best reflect the quality of global weather forecasts. As shown in the figure below, several of the ML-based forecasts have lower errors than the ML-based forecasts. state-of-the-art physical models on deterministic metrics. This holds for a range of variables and regions, and highlights the competitiveness and promise of ML-based approaches.
 |
| This scorecard shows the competence of different models compared to that of ECMWF. Integrated forecasting system (IFS), one of the best physics-based weather forecasts, for multiple variables. IFS forecasts are evaluated against IFS analysis. All other models are evaluated against ERA5. The order of ML models reflects the release date. |
Towards reliable probabilistic forecasts
However, a single forecast is often not enough. Time is inherently chaotic due to butterfly effect. For this reason, operational weather centers now run around 50 slightly perturbed runs of their model, called together, to estimate the probability distribution of forecasts under various scenarios. This is important, for example, if we want to know the probability of extreme weather events.
Creating reliable probabilistic forecasts will be one of the next key challenges for global ML models. Regional ML models, such as Google’s MetNet already estimates the probabilities. To anticipate this next generation of global models, WB2 already provides metrics and probabilistic baselines, including ECMWF IFS Packageto accelerate research in this direction.
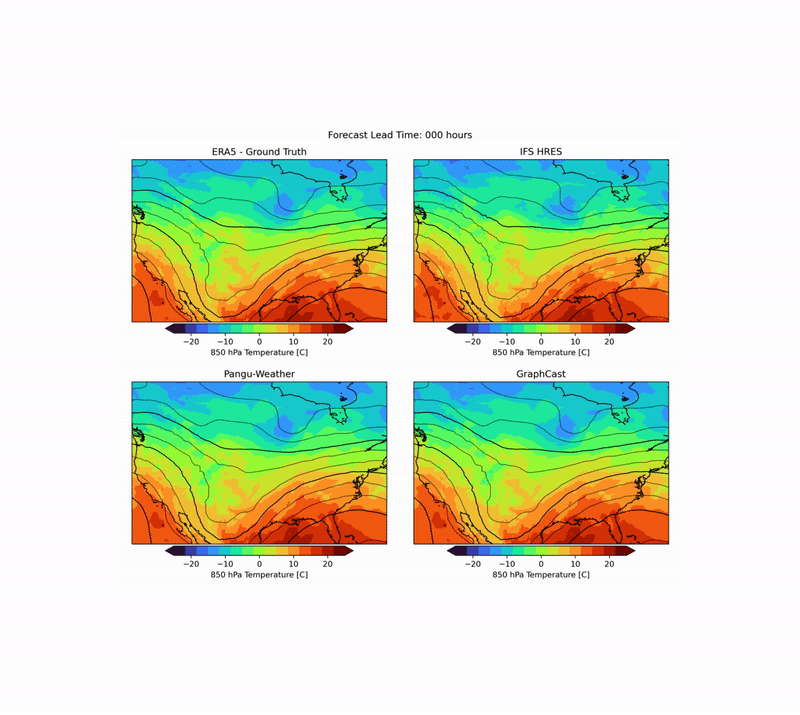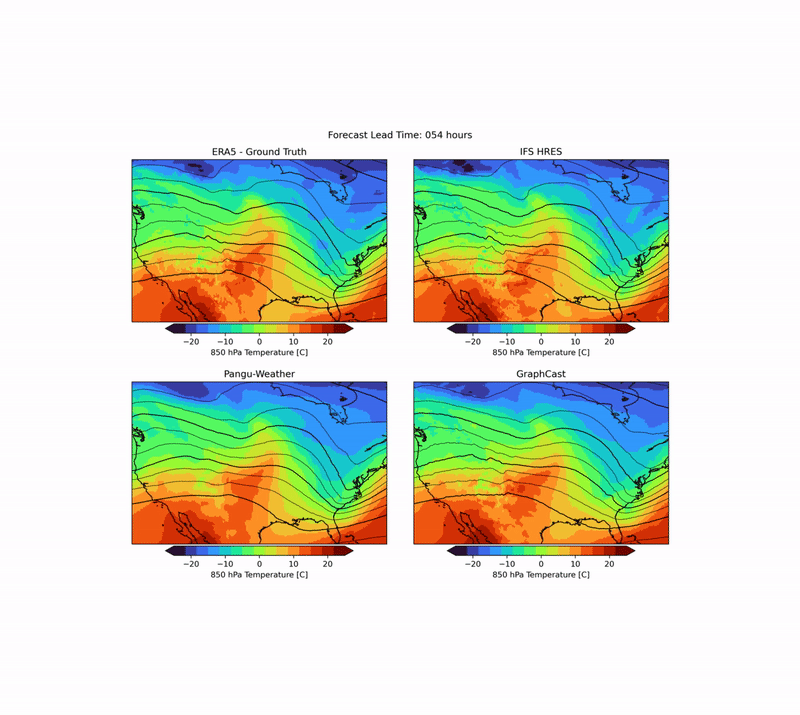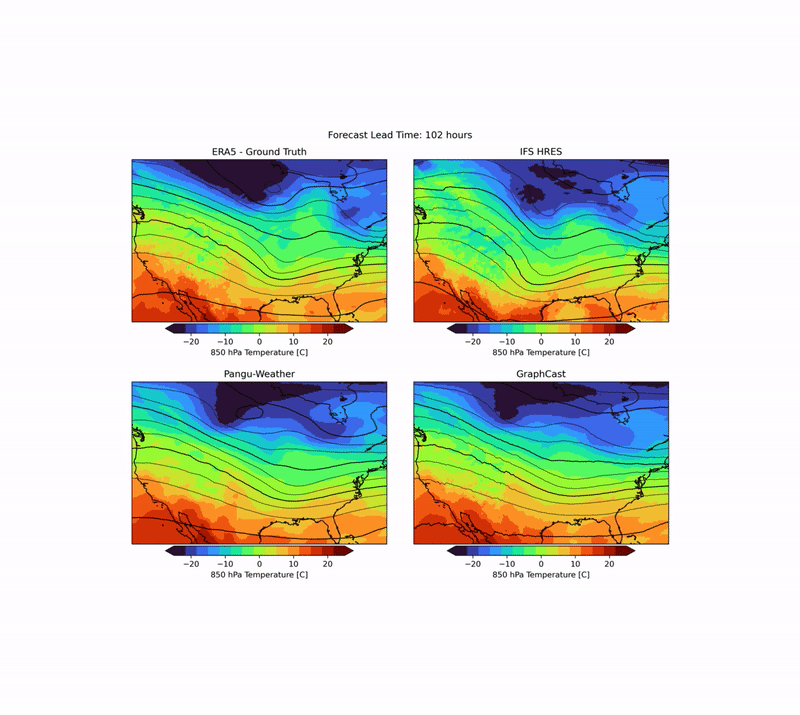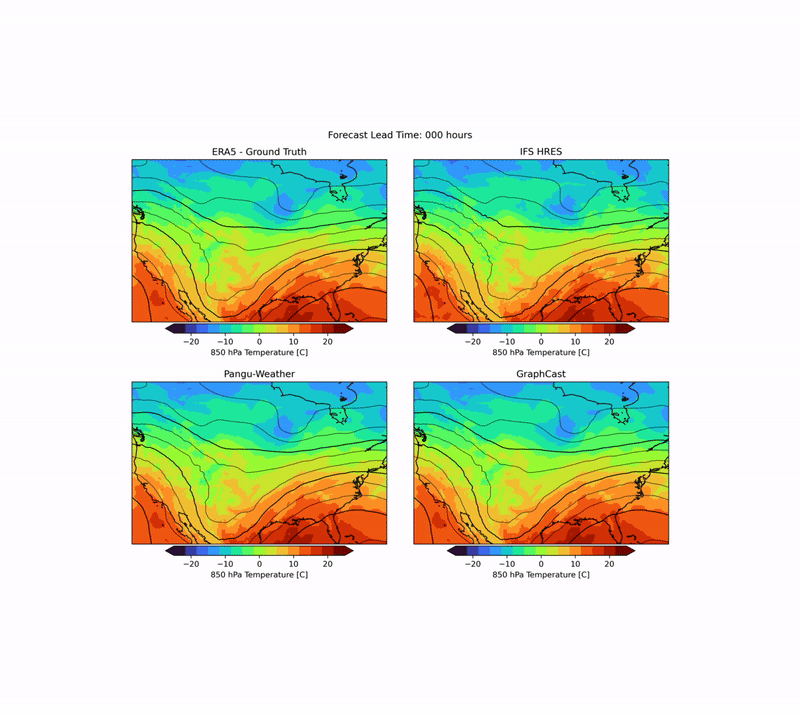
As mentioned above, there are many aspects to weather forecasting, and while leading indicators attempt to capture the most important aspects of forecasting skill, they are by no means sufficient. An example is the realism of forecasts. Currently, many ML forecast models tend to “hedge their bets” in the face of intrinsic uncertainty in the atmosphere. In other words, they tend to predict smoothed fields that give a lower average error but do not represent a realistic, physically consistent state of the atmosphere. An example of this can be seen in the animation below. The two data-driven models, Pangu-Weather and GraphCast (bottom), predict the large-scale evolution of the atmosphere remarkably well. However, they also have a less fine-scale structure compared to the ground truth or IFS HRES physical forecast model (top). In WB2, we include a series of these case studies as well as a spectral metric that quantifies this blurring.
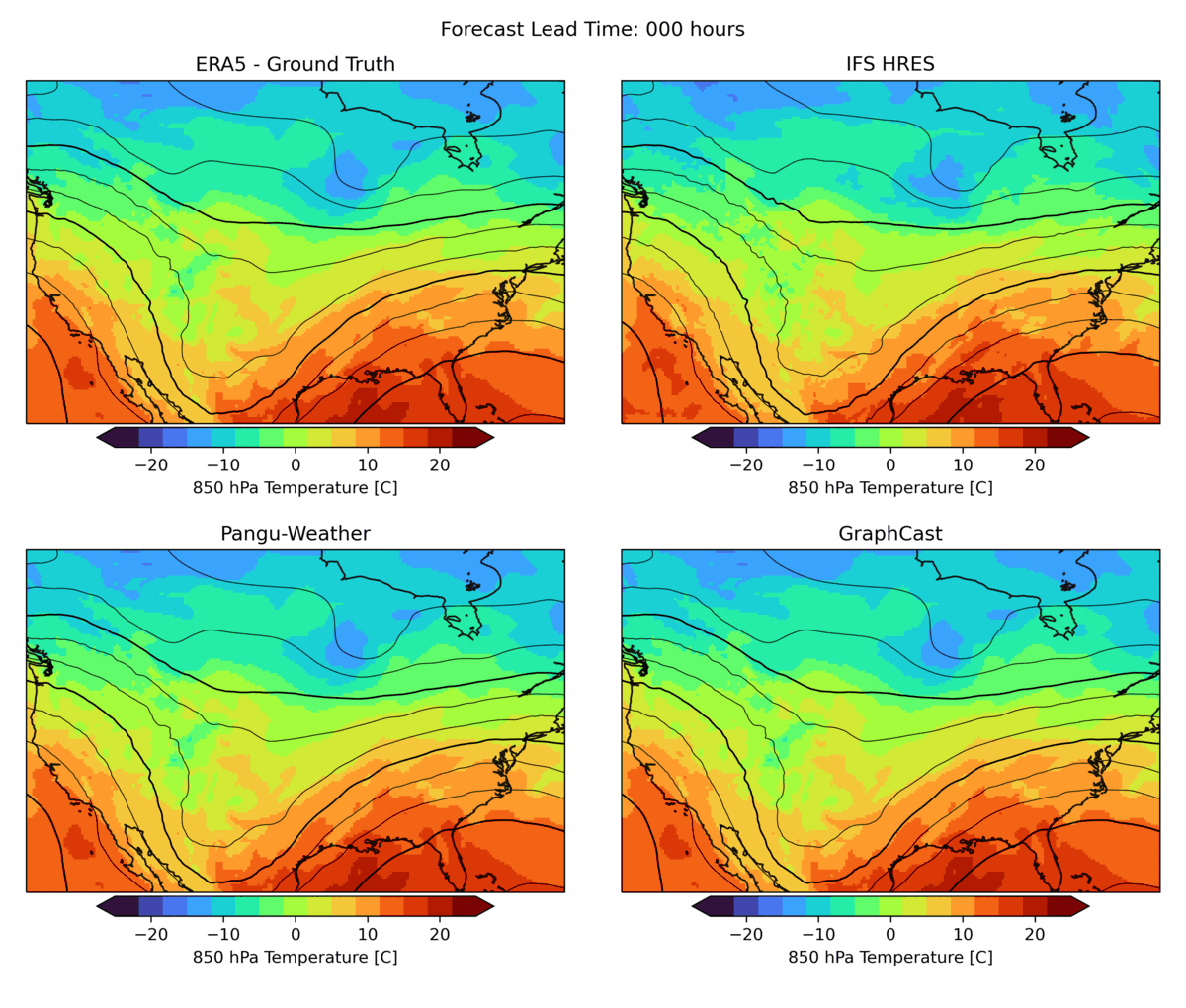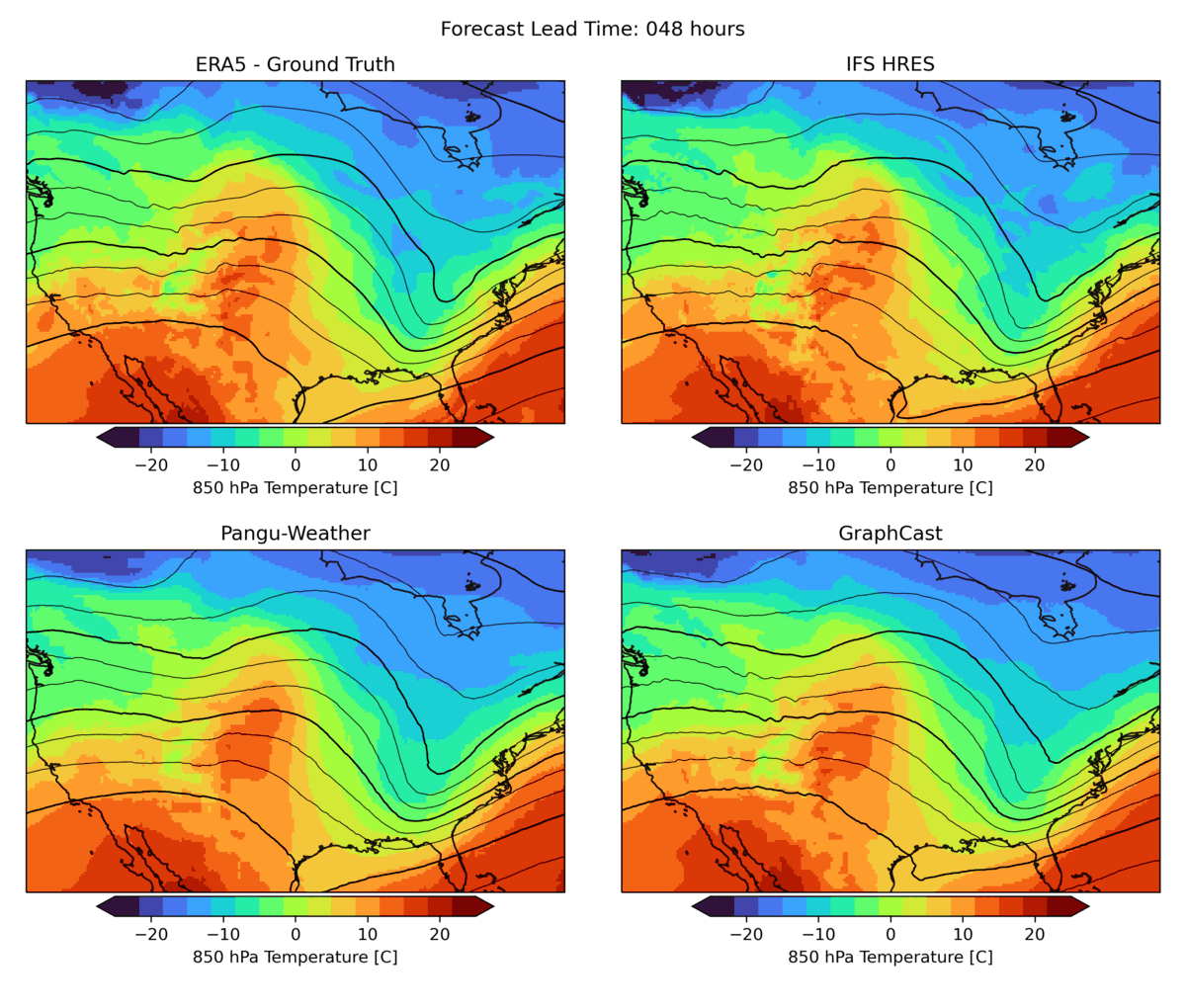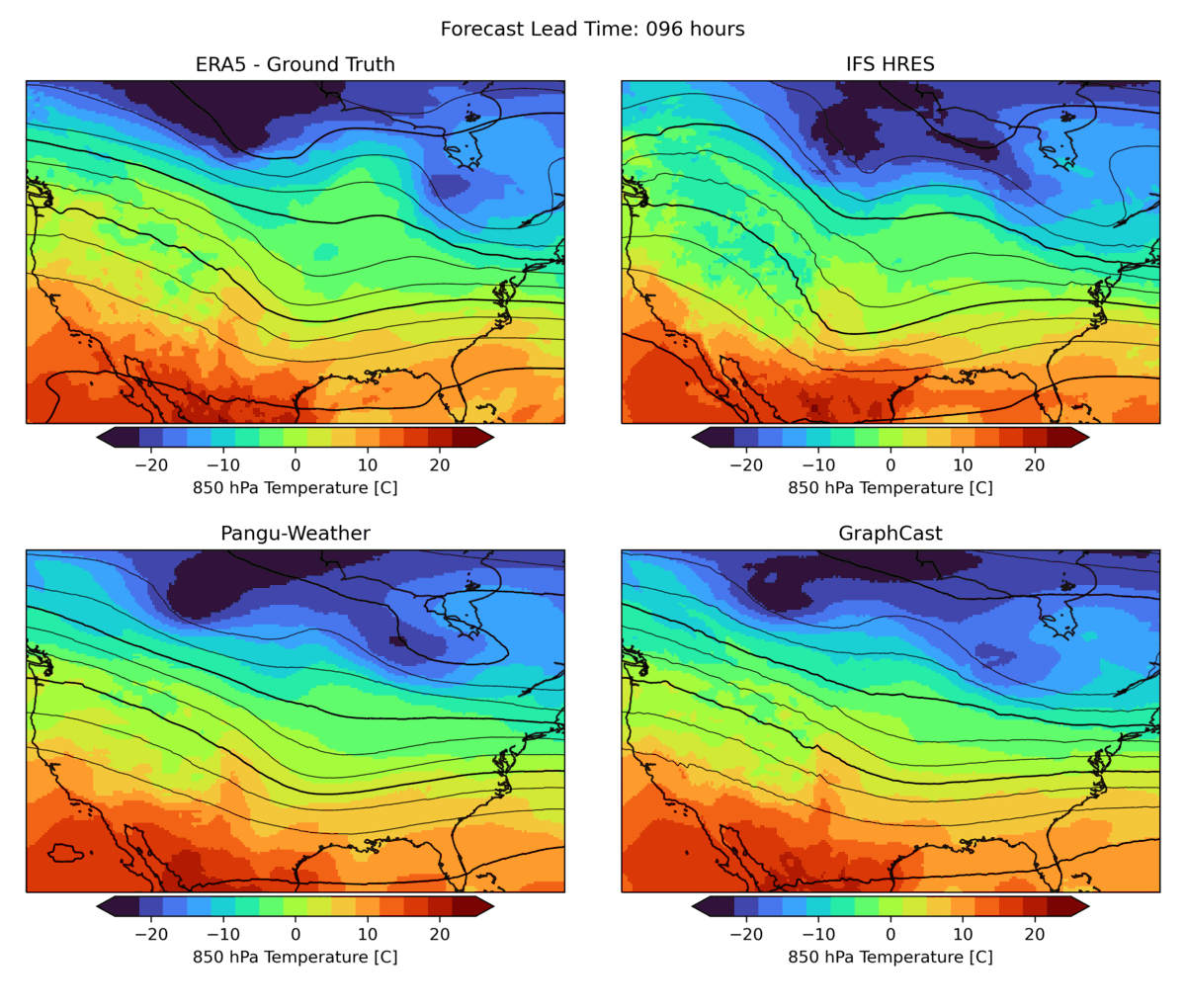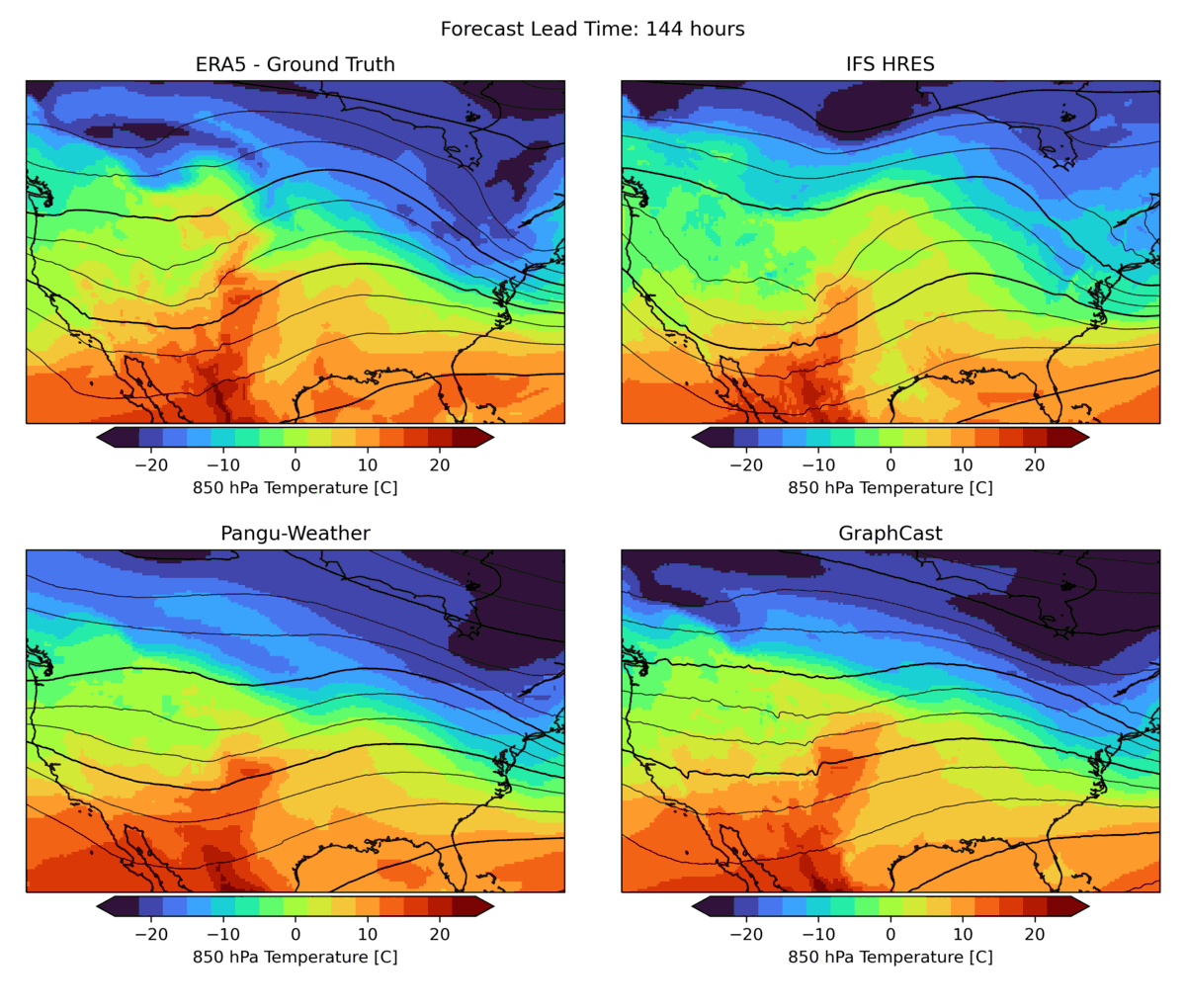 |
| Forecast of a front crossing the continental United States initialized on January 3, 2020. Maps show temperature at pressure level of 850 hPa (approximately the equivalent of an altitude of 1.5 km) and geopotential at a pressure level of 500 hPa (approximately 5.5 km) in contour lines. ERA5 is the corresponding ground truth analysis, IFS HRES is the ECMWF physics-based forecasting model. |
Conclusion
WeatherBench 2 will continue to evolve as the ML model develops. THE official website will be updated with the latest cutting-edge models. (To submit a template, please follow these instructions). We also invite the community to provide feedback and suggestions for improvement through issues and pull requests on the site. WB2 GitHub page.
Properly designing the assessment and targeting the right metrics is crucial to ensure that ML weather models benefit society as quickly as possible. WeatherBench 2 as it currently stands is just the starting point. We plan to extend it in the future to address key issues for the future of ML-based weather forecasting. Specifically, we would like to add station observations and better precipitation datasets. Additionally, we will explore the inclusion of nowcasts and subseasonal to seasonal forecasts in the benchmark.
We hope WeatherBench 2 can help researchers and end users as weather forecasts continue to evolve.
Thanks
WeatherBench 2 is the result of collaboration between many different teams at Google and external ECMWF collaborators. From ECMWF, we would like to thank Matthew Chantry, Zied Ben Bouallegue and Peter Dueben. On behalf of Google, we would like to thank the main contributors to the project: Stephan Rasp, Stephan Hoyer, Peter Battaglia, Alex Merose, Ian Langmore, Tyler Russell, Alvaro Sanchez, Antonio Lobato, Laurence Chiu, Rob Carver, Vivian Yang, Shreya Agrawal . , Thomas Turnbull, Jason Hickey, Carla Bromberg, Jared Sisk, Luke Barrington, Aaron Bell and Fei Sha. We would also like to thank Kunal Shah, Rahul Mahrsee, Aniket Rawat and Satish Kumar. Thanks to John Anderson for sponsoring WeatherBench 2. Additionally, we would like to thank Kaifeng Bi from the Pangu-Weather team and Ryan Keisler for their help in adding their models to WeatherBench 2.